W poprzednim wpisie pokazałem, jak dostać się do typowych, wspieranych przez .NET, rozszerzeń certyfikatów wersji 3. Wśród wspieranych brakuje jednak np. tak ważnego rozszerzenia jak informacje o punktach dystrybucji CRL. Bez dodatkowych bibliotek możemy zobaczyć tylko wersję „RAW” tego rozszerzenia, czyli tak na prawdę ciąg liczb 16-bitowych.
Jest to dobry moment, żeby zajrzeć do RFC opisującego budowę rozszerzenia i przyjrzeć się notacji ASN.1 oraz spróbować na tej podstawie zdekodować format DER, w którym zapisane jest to rozszerzenie.
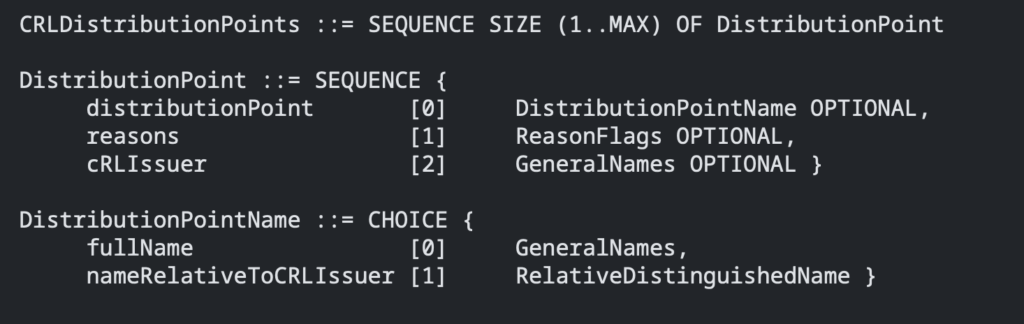
Interesujący nas dokument to RFC o numerze 5280. Znajdziemy tam opis jak poniżej.
id-ce-cRLDistributionPoints OBJECT IDENTIFIER ::= { id-ce 31 }
cRLDistributionPoints ::= SEQUENCE SIZE (1..MAX) OF DistributionPoint
DistributionPoint ::= SEQUENCE {
distributionPoint [0] DistributionPointName OPTIONAL,
reasons [1] ReasonFlags OPTIONAL,
cRLIssuer [2] GeneralNames OPTIONAL }
DistributionPointName ::= CHOICE {
fullName [0] GeneralNames,
nameRelativeToCRLIssuer [1] RelativeDistinguishedName }
ReasonFlags ::= BIT STRING {
unused (0),
keyCompromise (1),
cACompromise (2),
affiliationChanged (3),
superseded (4),
cessationOfOperation (5),
certificateHold (6),
privilegeWithdrawn (7),
aACompromise (8) }Jest to zapis w postaci ASN.1, czyli pewnym standardzie i notacji opisu danych. Jest to międzynarodowy standard i często można go spotkać w dokumentach RFC. Standard definiuje zbiór tzw. typów podstawowych, z których później komponowane są złożone typy danych.
Wśród typów podstawowych/prostych znajdziemy między innymi:
- BOOLEAN, INTEGER, REAL,
- ENUMERATED,
- CHARACTER STRING,
- UTCTime,
- OBJECT IDENTIFIER,
- NULL.
Typy danych zaczynają się wielką literą (te zdefiniowane w ramach standardu składają się z samych wielkich liter). Identyfikatory zaczynają się z małej litery.
Pośród zdefiniowanych typów złożonych znajdziemy:
- SEQUENCE – uporządkowana lista innych typów (niektóre elementy mogą być opcjonalne),
- SEQUENCE OF – lista elementów tego samego typu,
- CHOICE – typ złożony będący jednym z wymienionych możliwych typów (przykład zobaczymy za chwilę).
Każdemu typowi danych odpowiada etykieta (Tag) czyli numer, który jest używania przy zapisie struktury np. w postaci formatu DER. Kilka przykładów niżej.
| Etykieta (Tag) | Typ danych |
| UNIVERSAL 1 | BOOLEAN |
| UNIVERSAL 2 | INTEGER |
| UNIVERSAL 5 | NULL |
| UNIVERSAL 6 | OBJECT IDENTIFIER |
| UNIVERSAL 16 | SEQUENCE, SEQUENCE OF |
Analiza zapisu
Przyjrzyjmy się zatem zapisowi z RFC.
id-ce-cRLDistributionPoints OBJECT IDENTIFIER ::= { id-ce 31 }
cRLDistributionPoints ::= SEQUENCE SIZE (1..MAX) OF DistributionPoint
Widać tutaj, że analizowane rozszerzenie składa się z identyfikatora id-ce-cRLDistributionPoints i listy punktów dystrybucyjnych cRLDistributionPoints. Identyfikator jak widać ma wartość {id-ce 31}. Jeżeli poszukamy głębiej w dokumencie, znajdziemy definicję id-ce.
id-ce OBJECT IDENTIFIER ::= { joint-iso-ccitt(2) ds(5) 29 }Oznacza to, że pełny, liczbowy identyfikator rozszerzenia to 2.5.29.31. Poniżej listing programu z poprzedniego wpisu, gdzie widzimy, że certyfikat zawiera rozszerzenie o takim numerze.
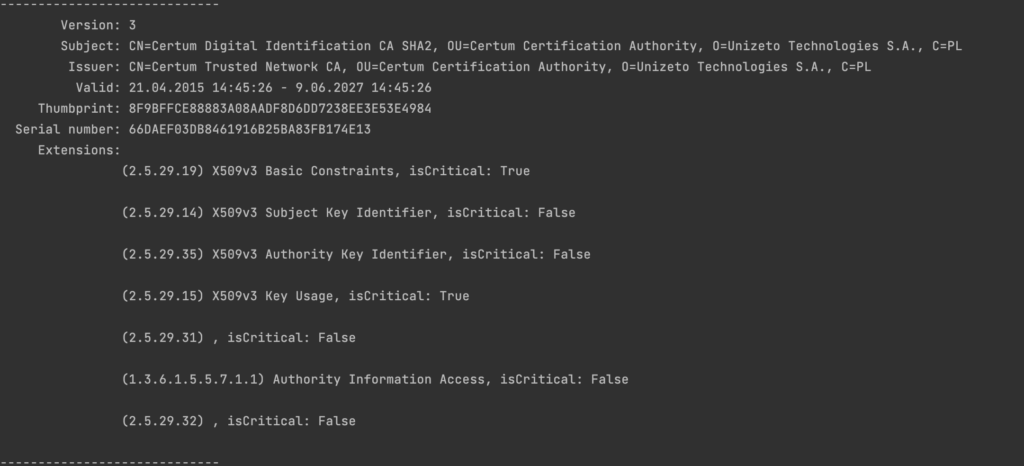
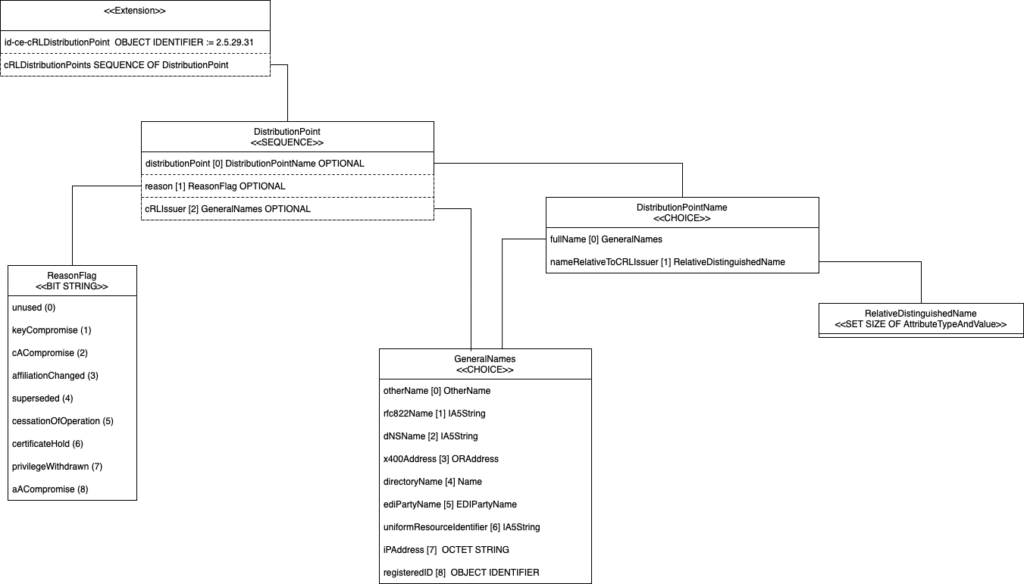
Dalsza część rozszerzenia to pole cRLDistributionPoints czyli sekwencja obiektów typu DistributionPoint. Taka struktura składa się z trzech następujących, opcjonalnych elementów – distributionPoint, reason oraz cRLIssuer.
DistributionPoint ::= SEQUENCE {
distributionPoint [0] DistributionPointName OPTIONAL,
reasons [1] ReasonFlags OPTIONAL,
cRLIssuer [2] GeneralNames OPTIONAL }Odpowiednie typy (DistributionPointName, Reasonflag oraz GeneralNames) są dalej zdefiniowane w analizowanym RFC. Widać tutaj, że przypisane są im wartości numeryczne widniejące w nawiasach klamrowych. Są to wartości tagów. Nas interesuje pierwsza z wymienionych struktur.
DistributionPointName ::= CHOICE {
fullName [0] GeneralNames,
nameRelativeToCRLIssuer [1] RelativeDistinguishedName }Jest to element typu CHOICE, czyli jest to jeden z wymienionych: fullName bądź nameRelativeToCRLIssuer. GeneralName też jest elementem jednym z wymienionych niżej typów.
GeneralName ::= CHOICE {
otherName [0] OtherName,
rfc822Name [1] IA5String,
dNSName [2] IA5String,
x400Address [3] ORAddress,
directoryName [4] Name,
ediPartyName [5] EDIPartyName,
uniformResourceIdentifier [6] IA5String,
iPAddress [7] OCTET STRING,
registeredID [8] OBJECT IDENTIFIER }Myślę, że idea została przedstawiona, nie musimy chyba analizować w ten sposób całości krok po kroku. Dołącze jeszcze poglądowy rysunek.
Dekodowanie DER
Skoro znamy strukturę rozszerzenia oraz tagi poszczególnych typów, możemy pokusić się o ręczne zdekodowanie zawartości certyfikatu.
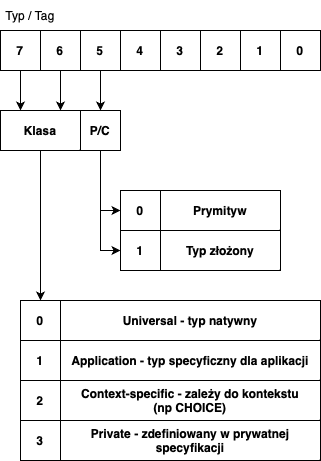
Format der jest dedykowany binarnemu zapisowi danych o strukturze zdefiniowanej za pomocą ASN.1. Ramka składa się z trzech elementów: Identyfikatora typu danych (Tag), informacji o wielkości danych i samych danych. Całość analizowana jest rekurencyjnie.

Kilka słów wyjaśnienia należy się polu Typ (Tag). Jest to ośmiobitowe pole, którego najbardziej znaczące bity niosą dodatkową informację.
Zatem załóżmy przykładowe rozszerzenie certyfikatu, zapisane w formacie DER.
30:26:30:24:A0:22:A0:20:86:1E:68:74:74:70:3A:2F:2F:63:72:6C:2E:63:65:72:74:75:6D:2E:70:6C:2F:63:74:72:63:61:2E:63:72:6CAnaliza takiego ciągu będzie wyglądała jak niżej.
